웹 어플리케이션 개발에서 대용량 엑셀 다운로드는 항상 골칫거리이다.
한 10만 레코드 정도만 받으려고 해도
1) 일단 레코드를 얻어서 객체로 들고 있는 단계에서 OutOfMemory가 나기도 하고
2) 이걸 간신히 객체로 만든 후에 POI 나 JXL 라이브러리로 Workbook을 생성해
데이터를 채워나가다가 OutOfMemory가 나기도 한다. (같은 데이터가 중복되는 셈이니 2배가 되어)
3) 게다가 메모리에 담고 있는 걸 요청자에게 송신하는 시간동안 꼼짝없이 메모리를 잡고 있게 된다.
대용량 컨텐츠를 보낼 때는 조금씩 끊어 보내면서 flush를 할 수 있어야 하는데 이게 안되는 게 문제.
그래서 보통 다음과 같이 하나하나씩 해결해 나간다.
- 위의 3)번은 일단 파일로 저장하고 이 파일을 다운로드 시켜주는 방식이 가능하다.
- 위의 2)번의 경우 Workbook을 생성해 Row를 채우는 데 쓰인 객체는 해제시켜줄 수 있겠다.
- 아예 Workbook을 생성하지 않고 HTML 로 보내면서 Microsoft Excel 어플리케이션이 열 수 있게
응답헤더만 조정하는 방법도 있다.
- 내게 시키는 고객과 잘 협의가 가능하다면 CSV (Comma Separated Values) 포맷으로 다운로드도
가능할 것이다. 고객 만족도는 엄청 떨어지겠지만.
그런데 이것들을 제대로 해결해 주는 녀석이 등장.
Apache POI 3.8-beta3 (2011년 6월) 버전부터 임시파일을 활용하여 메모리 사용량을 최저로 유지하는 기능이 추가되었다.
(Excel 2007부터 지원되는 xslx, 혹은 ooxml 포맷만 가능)
확인을 위해 테스트 소스를 작성해 보았다.
pom.xml 을 다음과 같이 구성하여 apache-poi를 사용 가능하게 한다.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>test</groupId>
<artifactId>test-poi-memory</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>test-poi-memory</name>
<dependencies>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.10-beta2</version>
</dependency>
</dependencies>
</project>
다음과 같이 소스를 짜 보았다.
public class ExcelWriteTest {
public static void main(String[] args) throws Exception{
OutputStream os = new FileOutputStream("c:/tmp/excelfile.xlsx");
// streaming workbook 생성
Workbook wb = new SXSSFWorkbook(100); // 100 row마다 파일로 flush
for(int sheetNum = 0; sheetNum < 6; sheetNum++){ // 시트 6개
Sheet sh = wb.createSheet();
Row heading = sh.createRow(1);
String[] columns = new String[]{"ID", "NAME", "GENDER", "ADDR", "TEL"};
for(int i = 0; i < columns.length; i++) {
Cell cell = heading.createCell(i+1);
cell.setCellValue(columns[i]);
}
for (int rowNum = 2; rowNum < 1048560; rowNum++){
Row row = sh.createRow(rowNum);
row.createCell(1).setCellValue("123123123123");
row.createCell(2).setCellValue("JOHN_CORNER_MARIE_TYPE_PILE_END");
row.createCell(3).setCellValue("MALE");
row.createCell(4).setCellValue("Dongjin-Gu, Pyeonsoo-dong, Daeum-chon 2348-112");
row.createCell(5).setCellValue("010-8422-9548");
}
}
wb.write(os);
os.close();
((SXSSFWorkbook)wb).dispose();
}
row의 내용들은 의미없이 양만 채운 것이고, 결과적으로 실행하고 나면 100메가 정도짜리 엑셀 파일이 만들어지게 조정했다.
그걸 만드는 몇 분 동안 VisualVM 으로 메모리 사용량을 체크했는데 실행 내내 다음과 같이 2MB 안쪽으로 밖에 쓰지 않는다.
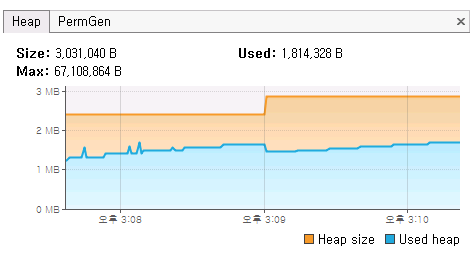
이걸 만들 때 주의할 것은, 시트(!)가 임시 저장소 (윈도우즈의 경우 환경변수 %TEMP% 로 정해진 위치, 유닉스라면 /tmp 일 듯) 에 압축되지 않은 채로 생기는데, 이게 꽤 양을 잡아먹는데다 위 코드의 마지막 줄 dispose() 를 실행하지 않으면 JVM이 종료된 후에도 파일이 사라지지 않는다.
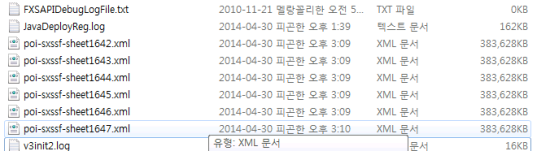
그러므로 dispose()는 꼭 해 주는 걸 권장한다.
다만 dispose()를 하게 되면 그 Workbook 객체는 쓸 수 없는 상태가 되므로 가능한 한 마지막(!)에..
... 이제 이걸 가지고 다음과 같이 하면 다운로드가 끝난다.
1) 예제처럼 (임시)파일로 저장하고 dispose()한 후, 이를 다운로드 시키고 파일을 삭제한다.
2) 아예 workbook 객체를 가지고 다운로드까지 한 후 dispose() 한다.
위 방법 중 1)번은 개발구조 상 layer가 명시적으로 나누어져 있어 layer 간 건네줄 정보가 String(파일위치) 이라는 등 한정적이거나, 파일을 생성후 다운로드 하는 짧(지만 짧지 않)은 시간 동안 디스크 공간 점유가 염려될 때 사용할 수 있겠다. 2)번은 그런 제약이 없을 경우 쓸 수 있고.
둘 다 모듈로 일반화 시키려면 적절한 코딩은 필요하고.. 특히 예외사항 (파일 생성 중 오류가 난다거나 파일 생성과 관계없는 곳에서 오류가 날 경우 임시파일의 뒤처리 등등) 에 대한 대응이 잘 짜여 있어야 하겠다.
[출처] 대용량 엑셀 다운로드에 대한 해답|작성자 우가가
'일 > Spring' 카테고리의 다른 글
| 자바 인코딩 테스트 코드 (0) | 2018.05.04 |
|---|---|
| ehcache 캐시 설정 (0) | 2018.01.11 |
| 스프링 트랜젝션 (transaction context) 설정 (0) | 2018.01.11 |
| JUnit 세팅 방법 및 참고 포스트 (0) | 2018.01.11 |
| mybatis interceptor 를 이용해서 쿼리 로그를 출력/디비에다 저장하기 (0) | 2017.04.27 |








